

 science-review.ru
science-review.ru
При современном ритме жизни у малого процента населения есть время для соблюдения правильного режима питания, вследствие чего организм получает избыток вредных веществ и недостаток необходимых, что негативно влияет на здоровье. Существует немало средств, позволяющих следить за показателями здоровья и одного из основных его факторов – питания, и одним из лучших методов для данной задачи является, на мой взгляд, методы машинного обучения.
Машинное обучение – класс методов искусственного интеллекта, характерной чертой которых является не прямое решение задачи, а обучение модели и получение решений для вводимых условий в процессе применения решений множества сходных задач [1]. При применении данных методов система «обучается» самостоятельному вычислению требуемых выходных функций и применению новых данных к этим функциям с последующим выводом результатов вычислений, что позволяет снизить потребность вмешательства человека в технологические процессы.
Рассмотрим задачу классификации пищевых продуктов питания, используя для этого методы машинного обучения. Имеется набор данных, представляющий собой количество основных параметров на 100 г продукта [2].
В зависимости от значений входных признаков нейронная сеть должна относить пример к тому или иному классу из 6 продуктов, а именно колбасные изделия, крупы и каши, молочные продукты, фрукты, овощи и зелень и мясные продукты.
Также, программа должна показывать точность работы нейронной сети.
Для решения данной задачи воспользуемся подвидом нейронной сети – персептроном.
Персептрон, – нейронная сеть прямого распространения сигнала (без обратных связей), в которой входной сигнал преобразуется в выходной, проходя последовательно через один/несколько слоев. Присутствие нескольких скрытых слоев оправдано лишь в случае использования нелинейных функций активации.
Перед управлением входными данными требуется подключить библиотеки для работы с машинным обучением на языке Python, а именно Tensorflow, Scikit-learn, Itertools, Numpy, Pandas и Matplotlib [3].
Сохраняем файл data.xlsx в формате .csv. В результате получили датасет из 542 примеров, которые необходимо классифицировать по классу продукта, к которому он относится.
Импортируем файл data.csv, предоставив ему имя в коде filename, по которому идёт обращение и считывание данных файла [4].
Для проверки верного считывания данных из файла выводим список, содержащий признаки и выходные значения для обработки.
В качестве оптимального эмпирическим путем был выбрана архитектура модели, – персептрон с 2 скрытыми сломи по 32 нейрона в каждом – 4 входных и 6 выходных.
Выведем графики попарного отношения входных признаков между собой, что покажет взаимное отношение признаков друг к другу в различных классах. Данный метод может быть полезен при выборке наиболее важных отношений признаков для обнаружения главных признаков и/или их корреляций. В данном случае, наблюдается несколько графиков, где большая часть классов идентична на основе двух признаков (жиры-калории, углеводы-калории), однако поскольку признаки взаимозависимы (калорийность зависит от количества белков, жиров, углеводов) сжатие данных ухудшит показатели точности обучения.
Пример входных данных
|
Продукт |
Белки, г |
Жиры, г |
Углеводы, г |
Калории, ккал |
|
Колбаса вареная диетическая |
12.10 |
13.50 |
0.00 |
170.00 |
|
Колбаса вареная докторская |
12.80 |
22.20 |
1.50 |
257.00 |
|
Колбаса вареная куриная |
15.50 |
16.20 |
2.30 |
223.00 |

Рис. 1. Код импорта датасета
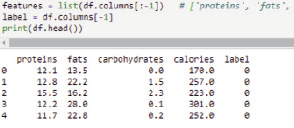
Рис. 2. Код вывода данных, считываемых из файла data.csv
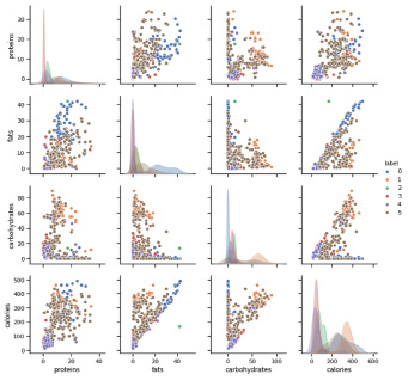
Рис. 3. Отображение классов в графах при попарной зависимости графиков от признаков

Рис. 4. Код создания модели персептрона
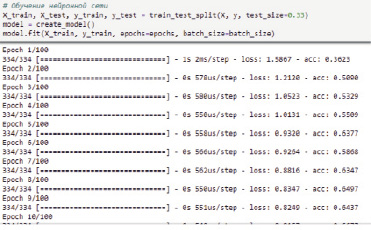
Рис. 5. Код обучения нейронной сети и результаты первых итераций

Рис. 6. Код предсказывания классов тестового набора, вывод точности классификации
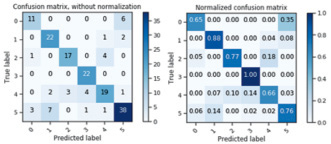
Рис. 7. Матрицы отношения предсказанных значений классов к истинным значениям
В качестве первого входных параметров на слой поступают данные с предыдущего слоя, которые получают собственный вес функцией активации ReLU (функция «выпрямителя», образует переход выхода функции в единицу при аргументе =<0) [5], и затем случайно исключаются методом DropOut (с вероятностью, вводимой разработчиком, исключает каждый нейрон на слое, что позволяет избавиться от проблемы переобучения сети), что позволяет избежать проблемы переобучения сети.
Для обучения и проверки обучаемости изменим представление созданного датасета: используя команду «train_test_split», разделяем изначальный набор данных на 2 набора – тренировочный (X_train, y_train) и тестовый (X_text, y_text) в соотношении 2/1 [6]. После чего инициируем ранее созданную модель персептрона в качестве обработчика, и используя команду «.fit()», применяем в каждому примеру созданную модель в течение заданного заранее количества итераций (эпох) в процессе выполнения команды.
На основе обучающего датасета применим модель классификатора, описанную ранее, и проверим точность предсказаний классов на тренировочном наборе; результат выполнения программы можно увидеть на рисунке [7].
После выполнения данных операций строим матрицы точности, которые показывают отношение (нормализованное или первоначальное число) предсказанных классов к истинным значениям в тренировочном наборе, которые можно увидеть на рисунке ниже: данные матрицы дают представление о том, насколько велика доля примеров из тестового набора, классифицированных верно (по-вертикали) к общему числу тестовых примеров, представленных в датасете (по-горизонтали).
Данные матрицы показывают, что лучше всего обученная сеть предсказывает 4-й класс (фрукты), хуже всего предсказание сказывается на 1 м классе (колбасные изделия) из-за схожих показателей входных данных между 1 м классом и классом № 6 (мясные изделия).
Выводы
В данной статье была проанализирована проблема классификации продуктов питания методами машинного обучения; обозначены основные понятия; описан метод обучения на основе многослойного персептрона. Экспериментальной частью являлось написание программы для получения точности классификации на основе тестового набора данных. Полученная программа показывает 80 % точности классификации и позволяет визуализировать данные для удобной работы с ними.
Библиографическая ссылка
Бруевич Н.А. РЕАЛИЗАЦИЯ КЛАССИФИКАТОРА ПРОДУКТОВ ПИТАНИЯ С ПОМОЩЬЮ МЕТОДА МАШИННОГО ОБУЧЕНИЯ // Научное обозрение. Педагогические науки. 2019. № 4-3. С. 30-34;URL: https://science-pedagogy.ru/ru/article/view?id=2113 (дата обращения: 27.07.2026).