

 science-review.ru
science-review.ru
Примерно 90 % информации человеческий мозг получает при помощи образов. Еще люди эпохи палеолита рисовали на стенах пещер различные образы, для сохранения и передачи информации. Со временем передача информации посредством живописи частично заменилась более универсальным способом, при помощи письменности.
Рукописный текст содержит алфавит букв, разделительные знаки. Фундаментальное свойство текста, которое делает возможным общение состоит в том, что отличия между разными символами более значительны, чем отличия между разными написаниями того же самого символа.
Человеческий почерк состоит из последовательных штрихов. Символы рукописного текста формируются последовательно, один символ завершается перед началом следующего. Но существуют и исключения – например, в русском языке точки над «ё» и черта над «й», как правило, задерживаются, сначала пишется основная часть слова, а потом слово завершается написанием точек или же запятых.
У всех букв есть статические и динамические свойства. Статистические свойства заключаются в форме и размере символа, а динамические заключаются в порядке и количестве штрихов. В русском языке больше вариантов в присутствии или отсутствии повторных штрихов. Повторный штрих – это штрих в месте, где что-то уже написано, обычно он делается, чтобы избежать поднимания ручки.
Существует множество задач распознавания образов для рукописного текста. Они охватывают отличия языковых символов, формул, например таких, которые используются при редактировании. Проблемы распознавания символов языка включают в себя, например, большие алфавиты китайских иероглифов, японские хирагану и катакану, арабские рукописные алфавиты и шрифты в западных языках. Но самой большой проблемой в распознавании рукописного текста являются трудности, которые вызывают у людей трудности прочитать даже собственный почерк.
Во-первых, это то, что большинство символов могут быть написаны по-разному. Например, на рис. 1 приведены разные возможные стили письма на китайском языке [1], которые современные системы могут без трудностей различать и распознавать. Также редко можно встретить двух людей с одинаковым почерком. Эта задача связана с различием шрифтов в классической задаче распознавания текста. Но в отличие от шрифтов, каждая буква в тексте одного человека может иметь свой собственный стиль в зависимости от контекста, в котором осуществляется написание окружающих букв.

Рис. 1. Возможные стили письма на китайском языке
Для решения данной проблемы современные системы используют самообучающиеся модули, которые обучаются различным почеркам людей и применяет уже эти данные при принятии решения.
Во-вторых, несколько символов могут выглядеть одинаково, либо практически не отличаются в почерке или некоторые буквы могут быть написаны неаккуратно, и быть похожими при этом на совершенно другие буквы. Эта проблема обычно решается использованием словарей, в которых программа может найти сомнительное слово, и таким образом можно избежать неточностей.
Более универсальным подходом к решению задачи о распознавании рукописного текста является нейросетевой. Нейронные сети – это модели биологических нейронных сетей мозга, в которых нейроны имитируются относительно простыми, часто однотипными, элементами. Идея нейронных сетей родилась в рамках теории искусственного интеллекта, в результате попыток имитировать способность биологических нервных систем обучаться и исправлять ошибки. Нейронные сети применяются в различных областях науки: начиная от систем распознавания речи до распознавания вторичной структуры белка, классификации различных видов рака и генной инженерии, автоматизации процессов распознавания образов, прогнозирования, адаптивного управления, создания экспертных систем, организации ассоциативной памяти, обработки аналоговых и цифровых сигналов, синтеза и идентификации электронных цепей и систем и т.д.
Самой популярной и широко исследуемой и применяемой нейронной сетью является сверточные нейронные сети – Convolutional Neural Network (CNN). CNN используют серию фильтров с необработанными пиксельными данными изображения для извлечения и изучения функций более высокого уровня, модель которой затем может использоваться для классификации. CNN состоит из сверточных слоев, объединенных слоев и плотных (полностью связанных) слоев (рис. 2) [2].
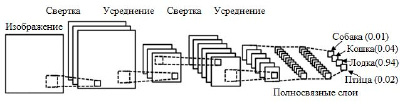
Рис. 2. Схематическое изображение сверточной нейронной сети
В нейросетевом подходе существует много разных других методов. Самыми популярными можно назвать рекуррентные нейронные сети [3], сеть Хопфилда [4] и многие другие.
Рекуррентные нейронные сети (recurrent neural networks, RNN) – это сети типа сетей прямого распространения, но с особенностью: нейроны получают информацию не только от предыдущего слоя, но и от самих себя предыдущего прохода. Это означает, что порядок, в котором вы подаёте данные и обучаете сеть, становится важным. Сети данного типа используются для автоматического дополнения информации.
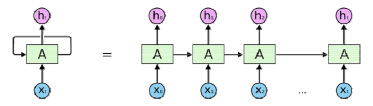
Рис. 3. Схематическое изображение рекуррентной нейронной сети
Нейронная сеть Хопфилда (Hopfield network, HN) – это полносвязная нейронная сеть с симметричной матрицей связей (рис. 4). Во время получения входных данных каждый узел является входом, в процессе обучения он становится скрытым, а затем становится выходом. Сеть обучается так: значения нейронов устанавливаются в соответствии с желаемым шаблоном, после чего вычисляются веса, которые в дальнейшем не меняются. После того, как сеть обучилась на одном или нескольких шаблонах, она всегда будет сводиться к одному из них. Данную сеть иногда называется сетью с ассоциативной памятью; как человек, видя половину таблицы, может представить вторую половину таблицы, так и эта сеть, получая таблицу, наполовину зашумленную, восстанавливает её до полной.
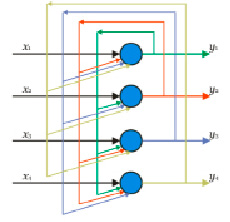
Рис. 4. Схематическое изображение нейронной сети Хипфилда
На сегодняшний день разработано много систем, которые демонстрируют возможности искусственных нейронных сетей: сети способные синтезировать человеческую речь, распознавать рукописные буквы, сжимать изображения. Большинство мощных сетей, которые ориентированы на распознавание символов и звуков берут за основу принцип обратного расширения, который является систематическим подходом для обучения многослойных сетей.
Каждый из разработанных алгоритмов обучения сетей имеет свои неоспоримые преимущества, но общим недостатком является ограничение в своих возможностях «обучаться» и «вспоминать».
Обучить нейронную сеть – означает, вычислить весовые коэффициенты связи нейронов одного слоя с нейронами другого слоя. Алгоритмы обучения подразделяются на обучение с учителем, без учителя и смешанное. Алгоритм обучения с учителем подразумевает использование эталонных значений в качестве выходных значений сети; при обучении без учителя выходными значениями являются реальные, вычисленные при подаче входного образа, значения. При смешанном подходе часть весовых коэффициентов определяется посредством обучения с учителем, в то время как остальная получается с помощью самообучения [5].
Обучение нейронных сетей, даже при использовании самых эффективных алгоритмов, представляет собой трудоемкий процесс, далеко не всегда дающий ожидаемые результаты. Проблемы возникают из-за нелинейных функций активации, образующих многочисленные локальные минимумы, к которым может сводиться процесс обучения.
На результаты обучения огромное влияние оказывает подбор начальных значений весов – инициализация нейронной сети. К сожалению, не существует универсального метода подбора весов, по этой причине в большинстве практических реализаций чаще всего применяется случайный подбор весов с равномерным распределением значений в заданном интервале.
Для повышения качества работы нейронной сети используются более сложные алгоритмы инициализации, например, такие как алгоритм имитации отжига, генетические алгоритмы, эволюционный алгоритм и т.д.
Важной частью любой системы распознавания символов является подсистема сегментации. Различие написанных слов в изображении и выделение букв в словах является довольно трудоемкой задачей, которая требует немало внимания, чем, собственно, сам процесс распознавания. Еще более важной является система выделения признаков, которая должна найти уникальные свойства выделенных букв и отбросить не нужные буквы. Современная машина распознавания рукописного текста не может существовать без словаря и подсистемы распознавания контекста. Они позволяют машине использовать внешние данные для решения конфликтных ситуаций, например, определение отличия между малыми и большими буквами или понимание неясно написанных символов.
Библиографическая ссылка
Маркин Е.И., Зупарова В.В., Сальников И.И. РАСПОЗНАВАНИЕ РУКОПИСНОГО ТЕКСТА С ИСПОЛЬЗОВАНИЕМ НЕЙРОННЫХ СЕТЕЙ // Научное обозрение. Педагогические науки. 2019. № 3-2. С. 44-47;URL: https://science-pedagogy.ru/ru/article/view?id=1953 (дата обращения: 25.07.2026).